Performance Optimization¶
Tóm tắt chung¶
Trong Odoo việc tối ưu hoá hiệu năng là công việc rất quan trọng. Nó giúp code tối ưu hơn, giúp tiêu tốn ít tài nguyên hệ thống hơn và chương trình hoạt động nhanh hơn. Các kĩ thuật được trình bày dưới đây sẽ giúp tối ưu hóa hiệu năng làm việc khi chạy chương trình!
Cơ chế nạp trước cho tập bản ghi¶
Khi bạn muốn truy cập dữ liệu từ một bản ghi nó sẽ thực hiện việc truy vấn vào cơ sở dữ liệu. Nếu bạn có một tập bản ghi có nhiều bản ghi thì nó sẽ thực hiện nhiều truy vấn cơ sở dữ liệu do đó làm cho hệ thống bị chậm đi. Do đó, Odoo cung cấp một cơ chế tìm nạp trước dữ liệu cho các bản ghi và trường để có được hiệu suất tốt. Các giá trị trả về sẽ được lưu trong bộ nhớ đệm để sử dụng. Các tập bản ghi được tìm nạp thường là các tập bản ghi mà trong đó các bản ghi được lặp lại (Ví dụ khi bạn sử dụng for với nhiều bản ghi). Các trường được tìm nạp là các trường được lưu trữ đơn giản (boolean, integer, float, char, text, date, datetime, selection, many2one).
Ví dụ:
for book in books:
print(book.name)
Với ví dụ trên giả sử books là tập bản ghi với 2000 bản ghi. Nếu không thực hiện cơ chế tìm nạp dữ liệu trước thì việc thực hiện vòng lặp này sẽ cần 2000 truy vấn cơ sở dữ liệu. Còn khi cơ chế tìm nạp dữ liệu trước thì chỉ có một truy vấn cơ sở dữ liệu được thực hiện.
Khi thực hiện book.name lần đầu tất cả các trường đơn giản của 2000 bản ghi sẽ được nạp vào bộ nhớ đệm bằng một truy vấn cơ sở dữ liệu.
Cơ chế tìm nạp trước cũng được thực hiện với các bản ghi thứ cấp.
Ví dụ:
for book in books:
author = book.author_id
print(author.name)
Với đoạn code như trên bạn chỉ cần 2 truy vấn vào cơ sở dữ liệu, một cho tất cả book và một cho tất cả author.
Bộ nhớ đệm – ormcache¶
Bộ nhớ đệm¶
Máy tính lưu dữ liệu chính vào 2 nơi đó là ổ cứng và RAM. Tốc độ đọc ghi của ổ cứng khoảng 50 - 250 MB/s thay vào đó với RAM là hàng chục GB/s. Do đó, chúng ta có thể nghĩ tới một giải pháp đó là lưu trữ tạm thời dữ liệu lên bộ nhớ RAM để tăng hiệu năng ứng dụng, việc lưu trữ tạm thời trên RAM thì người ta gọi là in-memory cache.
Bên cạnh lợi ích của In-Memory Cache thì nó cũng mang một số hạn chế như sau:
RAM có dung lượng hạn chế. Do đó cần cân nhắc dữ liệu nào nên được lưu trữ và khi đầy bộ nhớ thì xóa dự liệu nào đi.
Dữ liệu sẽ bị mất khi máy chủ khởi động lại hoặc bị ngừng.
Các thông số Cache Hit, Cache Miss sẽ ảnh hưởng tới việc áp dụng lưu trữ tạm thời. Bên cạnh đó cũng cần quan tâm tới Cache Replacement Policy để có thể tận dụng tối đa cache, giảm thiểu bộ nhớ.
Cache Hit¶
Cache hit chính là việc dữ liệu được yêu cầu đã được lưu trữ trong bộ nhớ cache. Đây là hình thức cung cấp dữ liệu với tốc độ nhanh chóng hơn cho bộ xử lý vì bộ nhớ cache lúc này đã chứa sẵn dữ liệu được yêu cầu đó rồi. Tỉ lệ cache hit càng cao thì cho thấy rằng sự quản lý cache của lập trình viên là rất tốt, nó đồng nghĩa với việc hệ thống cache đạt được tối ưu nhất.
Cache Miss¶
Ngược lại với cache hit thì chúng ta có cache miss, cache miss chính là việc dữ liệu được yêu cầu chưa được lưu trữ trong bộ nhớ cache. Đối với mỗi yêu cầu mới, bộ xử lý sẽ ưu tiên tìm kiếm dữ liệu đó trong primary cache trước tiên. Nếu dữ liệu không được tìm thấy tại đây, nó được coi là một cache miss. Trang thái cache miss càng cao thì đồng nghĩa với việc tăng thêm gánh nặng cho hệ thống của chúng ta. Việc áp dụng cache phải nên được đánh giá lại.
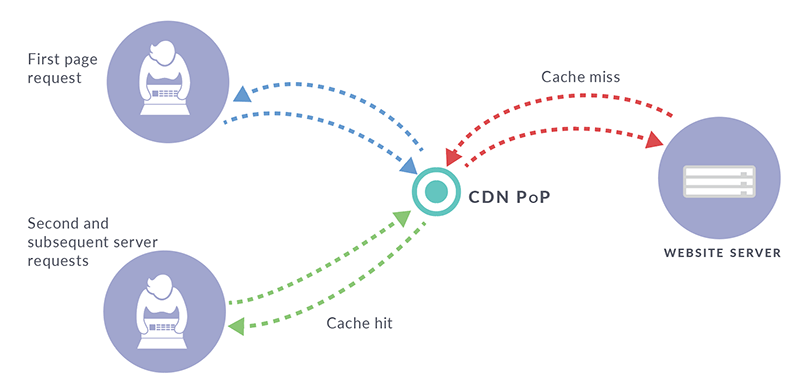
Cache Replacement Policy¶
Cache Replacement Policy là các thuật toán để thay thế giá trị hoặc xóa các giá trị cũ để thêm giá trị mới vào.
ORM Cache¶
Odoo cung cấp các decorator ormcache để quản lý lưu trữ trong bộ nhớ đệm. Muốn sử dụng chúng bạn chỉ cần import như sau:
from odoo import tools
Các decorator bao gồm:
ormcache decorator¶
Đây chính là decorator đơn giản và được sử dụng nhiều nhất.
Ví dụ:
@tools.ormcache('student')
def fetch_student_data(self, student):
# content of method
return data
Với decorator này, khi bạn gọi đến hàm fetch_student_data lần đầu tiên hàm sẽ thực hiện tính toán bình thường và trả về kết quả là data. ormcache sẽ lưu kết quả trả về này tương ứng với giá trị đầu vào của tham số student. Khi bạn thực hiện gọi lại hàm với giá trị của tham số như trên thì kết quả trả về sẽ lấy từ trong bộ nhớ đệm ra mà không cần thực hiện lại hàm trên.
Đôi khi kết quả của hàm còn phụ thuộc vào các thuộc tính của env. Kết quả của hàm sẽ được lưu vào bộ nhớ đệm dựa vào thuộc tính của env và giá trị của tham số. Với trường hợp như thế bạn có thể viết như sau:
@tools.ormcache('self.env.context', 'student')
def fetch_student_data(self, student):
# content of method
return data
ormcache_context decorator¶
Với decorator này kết quả trả về không chỉ phụ thuộc vào giá trị của tham số mà còn là các giá trị trong context. Ví dụ:
@tools.ormcache_context('student', keys=('active_id','lang'))
def fetch_data(self, student):
# some calculations
return data
ormcache_multi decorator¶
Một số hàm sẽ thực hiện trên nhiều bản ghi hoặc list các id. Khi bạn muốn thêm bộ nhớ đệm cho phương thức này có thể sử dụng decorator trên. Ví dụ:
@tools.ormcache_multi('student', multi='ids')
def fetch_data(self, student, ids):
data = {}
for i in ids:
val = ... # some calculation based on ids
data[i] = val
return data
ORM sẽ tạo các khóa của bộ nhớ đệm bằng việc lặp lại các giá trị trong tham số multi. Kết quả trả về ở định dạng dictionary với các phần tử có các khóa tương ứng trong tham số multi. Giả sử ids=[1, 2, 3] hàm sẽ thực hiện và kết quả trả về định dạng như sau {1: , 2: , 3: }. ORK sẽ lưu kết quả trả về vào bộ nhớ đệm tương ứng theo các khóa này. Lần tiếp theo khi bạn truyền vào ids=[1, 2, 3, 4, 5] hàm sẽ thực hiện tính toán với id là 4 và 5, còn các kết quả còn lại sẽ được lấy trong bộ nhớ đệm.
Bộ nhớ đệm hoạt động như nào¶
Các dữ liệu trong bộ nhớ đệm sẽ được lưu trữ dưới định dạng dictionary. Các khóa của chúng sẽ là các giá trị tham số đầu vào của hàm. Ví dụ: Khi gọi phương thức với tham số a và b, kết quả trả về là c. Dữ liệu sẽ được lưu trong bộ nhớ đệm như sau {(a, b): c}.
Warning
ORM cache là một bộ nhớ đệm, vì vậy nó được lưu trữ trong RAM. Không sủ dụng ormcache để cung cấp dữ liệu lớn như hình ảnh và tệp.
Các decorator này sẽ không bao giờ trả về một tập bản ghi.
Bạn nên sử dụng bộ nhớ đệm trên các hàm trả về cùng một kết quả với các tham số giống nhau. Còn nếu không bạn nên xóa bộ nhớ đệm một cách thủ công khi thực hiện.
self.env[model_name].clear_caches()
Ngoài ra¶
Tương ứng với ORM cache nó sử dụng Cache Replacement Policy là Least Recontly Used (LRU). Với thuật toán này các dữ liệu có khóa không được sử dụng thường xuyên sẽ bị xóa trong bộ nhớ đệm. Nếu bạn không sử dụng bộ nhớ đệm ORM đúng cách sẽ có thể gây hại cho ứng dụng. Khi mà tham số truyền vào hàm luôn khác nhau, Odoo sẽ tìm kiếm trong bộ nhớ đệm trước sau đó mới gọi hàm để tính toán.
Nếu muốn tìm hiểu bộ nhớ đệm của chương trình đang chạy như nào bạn có thể thêm như sau vào quá trình chạy:
kill -SIGUSR1 496
496 ở đây chính là ID tiến trình. Sau khi thực hiện sẽ có kết quả phân tích số cache hit, cache miss trong logs như sau:
> 2022-01-14 07:28:51,237 69920 INFO book-db-14 odoo.tools.cache:
1 entries, 31 hit, 1 miss, 0 err, 96.9% ratio,
for ir.actions.act_window._existing
> 2022-01-14 07:28:51,237 69920 INFO book-db-14 odoo.tools.cache:
1 entries, 1 hit, 1 miss, 0 err, 50.0% ratio,
for ir.actions.actions.get_bindings
> 2022-01-14 07:28:51,237 69920 INFO book-db-14 odoo.tools.cache:
4 entries, 1 hit, 9 miss, 0 err, 10.0% ratio,
for ir.config_parameter._get_param
Tạo hình ảnh với các kích thước khác nhau¶
Nếu ai đã từng làm Website hoặc SEO thì cũng hiểu rằng với hình ảnh có kích thước lớn sẽ gây rắc rối cho website như nào. Chúng làm tăng kích thước của trang web và khiến chúng chậm đi. Điều này làm cho SEO ‘xấu’ và lượng khách truy cập cũng giảm dần. Với phần này sẽ tìm hiểu cách tạo ra các hình ảnh với kích cỡ khác nhau để sử dụng phù hợp. Từ đó có thể giảm kích thước của trang web và cải thiện thời gian tải trang.
Đầu tiên bạn cần kế thừa vào model image.mixin:
class School(models.Model):
_name = 'school'
_description = 'School'
_inherit = ['image.mixin']
Hình ảnh với các kích thước khác nhau hoạt động như nào¶
Mixin sẽ tự động thêm năm field vào model ‘school’ để lưu trữ các hình ảnh kích thước khác nhau:
image_1920: 1920x1920
image_1024: 1024x1024
image_512: 512x512
image_256: 256x256
image_128: 128x128
Trong năm field trên thì chỉ có field image_1920 là có thể chỉnh sửa. Các trường còn lại là read-only và sẽ được tự động cập nhật khi field image_1920 thay đổi. Do đó, trong giao diện form bạn cần sử dụng field image_1920 để người dùng có thể tải lên hoặc chỉnh sửa ảnh. Nhưng sử dụng hình ảnh image_1920 sẽ gây chậm trang web. Tuy nhiên có với việc sử dụng hình ảnh image_1920 nhưng hiển thị với kích thước nhỏ hơn sẽ cải thiện hiệu suất.
<field name="image_1920" widget="image" options="{'preview_image': 'image_128'}" />
Note
Model ‘image.mixin’ là AbstractModel nên bảng của nó sẽ không được lưu trong cơ sở dữ liệu. Nếu muốn sử dụng bạn cần kế thừa nó trong model của mình.
Với model image.mixin này bạn có thể lưu hình ảnh với độ phân giải tối đa là 1920x1920. Khi bạn lưu ảnh với độ phân giải cao hơn thì Odoo cũng sẽ xử lý để giảm độ phân dải xuống. Nhưng Odoo vẫn sẽ giữ đúng tỉ lệ ảnh khi bạn tải lên. Ví dụ: nếu bạn tải một hình ảnh có độ phân giải là 2000x1500 thì ảnh sẽ được lưu vào trường image_1920 có độ phân giải là 1920x1440.
Ngoài ra¶
Bạn vẫn có thể sử dụng hình ảnh ở các độ phân giải khác nhau:
image_3000 = fields.Image("Image 3000", max_width=3000, max_height=3000)
Còn nếu bạn muốn khai báo một field liên kết đến field image_1920 thì bạn cần kế thừa vào model image.mixin và related=”image_1920”.
image_1000 = fields.Image("Image 1000", related="image_1920")
Truy cập dữ liệu được nhóm¶
Với việc làm báo cáo bạn cần tìm kiếm các bản ghi và nhóm chúng lại theo tiêu chí một cách thủ công. Do đó sẽ tốn nhiều thời gian và làm chậm ứng dụng. Trong trường hợp này, bạn có thể sử dụng read_group() để truy cập dữ liệu được nhóm.
Note
Hàm read_group() được sử dụng nhiều để thống kê và trong các ‘smart button’
Ví dụ:
Bạn muốn làm một smart button hiển thị số lượng học sinh trên giao diện form của một lớp học. Bạn cần tìm kiếm tất cả các học sinh trong lớp đó và đếm chúng.
# trong model class.room
student_count = fields.Integer(compute='_compute_student_count',
string='Student Count')
def _compute_student_count(self):
students = self.env['student'].search([('class_room_id', 'in', self.ids)]) # 1 truy vấn SQL
for r in self:
r.student_count = len(students.filtered(lambda s: s.class_room_id.id == r.id)) # 1 truy vấn SQL lần đầu, lần hai sẽ lấy từ trong bộ nhớ đệm
Với ví dụ trên nếu dữ liệu của học sinh và lớp học ít thì việc áp dụng read_group() sẽ không có nhiều khác biệt. Nhưng nếu dữ liệu lớn thì đó thực sự là một vấn đề. Khi đó bạn có thể sử dụng read_group() như sau:
# in class.room model
student_count = fields.Integer(compute='_compute_student_count',
string='Student Count')
def _compute_student_count(self):
student_data = self.env['student'].read_group([('class_room_id', 'in', self.ids)],
fields=['class_room_id'], groupby=['class_room_id']) # 1 truy vấn SQL bởi GROUP BY
mapped_data = dict([(m['class_room_id'][0], m['class_room_id_count']) for m in student_data])
for r in self:
r.so_count = mapped_data[r.id]
Truy cập dữ liệu được nhóm hoạt động như nào¶
Bạn có thể tùy chỉnh hàm read_group() với các đối số khác nhau.
def read_group(self, domain, fields, groupby, offset=0, limit=None, orderby=False, lazy=True)
Ngoài ra¶
Việc nhóm theo date field có thể phức tạp hơn thay vì vậy bạn có thể nhóm theo ngày, tuần, tháng, quý, năm.
self.env['student'].read_group([], ['total:sum(score)'], ['birthday:month'])
Tạo hoặc chỉnh sửa tập bản ghi¶
Tạo nhiều bản ghi¶
Odoo hỗ trợ việc tao nhiều bản ghi một lúc thay vì tạo từng bản ghi. Trong hàm create() thay vì truyền vào một dictionary để tạo một bản ghi thì bạn cũng có thể truyền vào một danh sách các dictionary để tạo nhiều bản ghi.
vals = [
{
'name': 'Son'
'age': 18,
},
{
'name': 'Thong'
'age': 19,
}]
self.env['student'].create(vals)
Chỉnh sửa tập bản ghi¶
Việc sử dụng hàm write() cách thức hoạt động từ phiên bản 13 đã được thay đổi. Odoo sẽ không ghi thẳng dữ liệu vào cơ sở dữ liệu ngay tức khắc mà sẽ ghi dữ liệu khi cần hoặc khi gọi lệnh flush(). Đây là ví dụ về việc ghi dữ liệu từng bản ghi và một tập bản ghi.
# Example 1
data = {...}
for record in recordset:
record.write(data)
# Example 2
data = {...}
recordset.write(data)
Nếu bạn đang sử dụng Odoo với phiên bản 13 trở lên thì sẽ không có vấn đề gì về hiệu năng. Nhưng nếu bạn sử dụng phiên bản cũ hơn thì việc ghi từng bản ghi sẽ thực hiện nhiều truy vấn SQL hơn là ghi dữ liệu một tập bản ghi do có vòng lặp.
Tạo hoặc sửa tập bản ghi hoạt đông như nào¶
Khi bạn tạo một tập bản ghi, Odoo sẽ thực thi mỗi bản ghi một truy vấn SQl. Điều đó có nghĩa việc tạo một tập bản ghi sẽ không thực hiện một truy vấn SQL. Nhưng việc cải thiện hiệu suất sẽ được chú ý ở các compute field sẽ được thực hiện hàng loạt.
Còn với việc ghi dữ liệu cho tập bản ghi, Odoo sẽ xử lý tự động và sẽ có một truy vấn SQL được thực thi. Nếu trong cùng một transaction việc ghi lại dữ liệu cho cùng bản ghi sẽ được Odoo xử lý như sau:
student.name= 'Dung'
student.age= 20
student.name= 'Hieu'
student.age= 21
Với đoạn code trên, việc ghi dữ liệu sẽ được cập nhật vào bộ nhớ đệm. Cuối cùng chỉ có một truy vấn SQL được thực thi cho việc cập nhật name= Hieu và age= 21.
Khi bạn muốn đẩy dữ liệu từ bộ nhớ đệm vào cơ sở dữ liệu thì có thể sử dụng hàm flush():
student.name= 'Dung'
student.age= 20
student.flush()
student.name= 'Hieu'
student.age= 21
Với đoạn code trên thì sẽ có hai truy vấn được thực thi. Một truy vấn SQL thực hiện trước khi flush() và một truy vấn SQL thực hiện sau khi flush().
Ngoài ra¶
Với Odoo phiên bản nhỏ hơn 13 thì việc thực hiện ghi dữ liệu sẽ thực hiện truy vấn SQL ngay. Do đó với các phiên bản nhỏ hơn nên viết như sau:
# Không nên (2 truy vấn SQL)
student.name= 'Sang'
student.age= 15
# Nên (1 truy vấn SQL)
recordset.write({'name': 'Sang', 'age'= 15})
Truy cập bản ghi trông qua truy vấn cơ sở dữ liệu¶
ORM cung cấp các phương thức để làm việc với cơ sở dữ liệu nhưng do cơ chế hoạt động khiến nó trở nên chậm hơn truy vấn trực tiếp vào cơ sở dữ liệu. Với việc thực hiện truy vấn trực tiếp vào cơ sở dữ liệu bạn cần thực hiện như sau:
Bạn có thể thực hiện câu truy vấn với hàm self._cr.execute
self.flush()
self._cr.execute("SELECT id, name, age FROM student WHERE age < 20")
data = self._cr.fetchall()
print(data)
OUTPUT:
[(1, 'Sang', 15), (7, 'Son', 18), (8, 'Thong', 19)]
Kiểu dữ liệu trả về sẽ định dang kiểu list of tuple. Trong trường hợp bạn muốn dữ liệu trả về được định dạng kiểu list of dictionary thì cần sử dụng hàm dictfetchall().
self.flush()
self._cr.execute("SELECT id, name, age FROM student WHERE age < 20")
data = self._cr.dictfetchall()
print(data)
OUTPUT:
[{'id'=1, 'name': 'Sang', 'age': 15), {'id'=7, 'name': 'Son', 'age': 18), {'id'=8, 'name': 'Thong', 'age': 19)]
Nếu bạn chỉ muốn lấy dữ liệu của một bản ghi bạn có thể sử dụng hàm fetchone() và dictfetchone().
Truy cập bản ghi thông qua truy vấn cơ sở dữ liệu hoạt động như nào¶
Có hai cách để truy cập đến con trỏ của cơ sở dữ liệu từ tập bản ghi. Một là từ chính tập bản ghi self._cr, hai là truy cập từ môi trường self.env._cr. Con trỏ này được sử dụng để truy vấn cơ sở dữ liệu.
Rất nhiều chỗ sử dụng self.flush() trước khi thực hiện một truy vấn. Lý do là Odoo sử dụng bộ nhớ đệm để lưu dữ liệu do đó có thể dữ liệu trong cơ sở dữ liệu có thể chưa chính xác. self.flush() sẽ đẩy tất cả các dữ liệu trong bộ nhớ đệm vào cơ sở dữ liệu từ đó bạn sẽ nhận được giá trị chính xác trong cơ sở dữ liệu.
Nếu bạn đang thực hiện các truy vấn INSERT hoặc UPDATE, bạn cần thực thi flush() sau khi thực hiện truy vấn. Bởi vì ORM có thể không biết về các thay đổi bạn đã thực hiện và nó có thể đã có trong bộ nhớ đệm.
Bạn chỉ nên thực hiện các câu truy vấn trực tiếp vào cơ sở dữ liệu khi ORM không thể xử lý được nhu cầu của bạn. Bởi vì khi bạn thực hiện truy vấn trực tiếp bạn đang bỏ qua các quy tắc bảo mật và lợi thế về hiệu năng của ORM mang lại. Điều nguy hiểm hơn cả chính là việc tạo ra các lỗ hổng SQL Injection cho phép kẻ xấu tấn công vào cơ sở dữ liệu.
# Không nên, SQL injection
self.env.cr.execute('SELECT id, name FROM student WHERE name ilike + search_keyword + ';')
# Nên
self.env.cr.execute('SELECT id, name FROM student WHERE name ilike %s ';', (search_keyword,))
Không sử dụng hàm định dạng chuỗi vì nó sẽ cho phép kẻ tấn công thực hiện. Hơn nữa việc sử dụng truy vấn SQL khiến khó đọc, khó hiểu và rất khó bảo trì.
Note
Rất nhiều lập trình viên nghĩ rằng việc thực hiện truy vấn SQL làm cho ứng dụng hoạt động nhanh hơn vì qua bỏ ORM. Tuy nhiên điều này không hoàn toàn đúng và nó còn phụ thuốc vào tùy trường hợp. Trong hầu hết trường hợp, ORM thực hiện tốt hơn và nhanh hơn các truy vấn thủ công, bởi vì dữ liệu được cung cấp từ bộ nhớ đệm của tập bản ghi.
Ngoài ra¶
Các thao tác được thực hiện trong một giao dịch chỉ được commit khi kết thúc một transaction. Nếu xảy ra lỗi trong ORM, transaction sẽ được khôi phục. Nếu bạn thực hiện một truy vấn INSERT hoặc UPDATE và bạn muốn đặt nó thành vĩnh viễn thì có thể sử dụng self._cr.commit() để thực hiện các thay đổi.
Note
Việc sử dụng commit() có thể gây nguy hiểm vì nó có thể đặt bản ghi trong trạng thái không nhất quán. Lỗi trong ORM có thể gây ra quá trình khôi phục không đầy đủ, vì vậy chỉ sử dụng commit() nếu bạn hoàn toàn hiểu những gì mình làm.
Nếu bạn đang sử dụng commit() thì bạn không cần sử dụng flush() sau đó.
Profile Python code¶
Đôi khi bạn sẽ không thể xác định nguyên nhân của vấn đề. Điều này đặc biệt đúng với các vấn đề về hiệu suất. Do đó Odoo cung cấp một số công cụ giúp bạn tìm ra nguyên nhân thực sự của vấn đề.
Hãy thực hiện như sau:
from odoo.tools.profiler import profile
Sau đó bạn có thể sử dụng decorator profile cho hàm của bạn:
@profile
def make_available(self):
if self.state != 'lost':
self.write({'state': 'available'})
return True
Khi hàm trên được gọi nó sẽ phân tích và ghi vào log:
calls queries ms
library.book ------------------------ /Users/pga/odoo/
test/student/models/student.py, 30
1 0 0.01 @profile
def make_available(self):
1 3 12.81 if self.state != 'lost':
1 7 20.55 self.write({'state': 'available'})
1 0 0.01 return True
Total:
1 10 33.39
Profile decorator hoạt đông như nào¶
Với kết quả như trên, cột đầu tiên hiển thị số lượng hàm được gọi. Cột thứ hai hiển thị số lượng truy vấn được thực hiện. Cột thứ ba hiển thị thời gian của dòng đó tính bằng mili giây. Lưu ý thời gian hiển thị chỉ là tương đối, nó sẽ nhanh hơn khi profile tắt.
Decorator này cung cấp một số tùy chọn có thể thay đổi theo ý muốn.
def profile(method=None, whitelist=None, blacklist=(None,), files=None,
minimum_time=0, minimum_queries=0):
Chi tiết:
whitelist: Tham số này sẽ nhận vào danh sách (list) tên model để hiển thị trong log.
files: Tham số này sẽ nhận danh sách (list) các tên tập tin để hiển thị.
blacklist: Tham số này sẽ nhận danh sách (list) tên model không muốn hiện thị trong log.
minimun_time: Tham số này nhận một giá trị nguyên (mili giây), nó sẽ ẩn log có tổng thời gian nhỏ hơn số lượng nhập vào.
minimun_querys: Tham số này sẽ nhận một giá trị nguyên, nó sẽ ẩn log có tổng truy vấn nhỏ hơn số lượng nhập vào.
Ngoài ra¶
Odoo cung cấp một decorator nữa trong thư mục misc. Nó sẽ tạo ra một tệp với dữ liệu thống kê theo đồ thị.
from odoo.tools.misc import profile
...
@profile('/Users/parth/Desktop/make_available.profile')
def make_available(self):
if self.state != 'lost':
self.write({'state': 'available'})
self.env['student'].create({'name': 'Quang', 'age': 25})
return True
Khi hàm make_available được gọi, nó sẽ tạo một tệp trên Desktop. Để chuyển đổi dữ liệu thành biểu đồ, bạn cần cài đặt công cụ gpof2dot và thực hiện lệnh sau:
gprof2dot -f pstats -o /Users/parth/Desktop/prof.xdot /Users/parth/Desktop/make_available.profile
Sau đó sẽ tạo ra tệp prof.xdot trên Desktop. Để hiển thị thực hiện như sau:
xdot /Users/parth/Desktop/prof.xdot